리눅스 스케줄링 정책(Linux Scheduling Policy)

리눅스에는 어떤 프로세스가 다음에 실행될까. 물론 우선순위가 제일 높은 프로세스가 실행될 것이다. 하지만 한 가지 고려사항이 더 있다. 그것은 프로세스가 remaining time slice를 갖고 있는지 여부이다.

위 템플릿을 보자. ① 박스 안에 Task에게 CPU를 줄 때는 무제한으로 할당하는 게 아니라, 위 템플릿에서는 100ms 시간만 해당 Task에게 CPU를 할당한다. 즉, 한 번 할당받으면 100ms 시간만큼 CPU를 사용해야 한다. 그런데 불행하게도 100ms 를 사용하기도 전에 급히 처리해야 될 task가 있어서 100ms를 다 못쓰고 CPU를 빼았겨 버린다. ① 에서는 20ms만 쓰고 80ms는 사용하지 못한 채 CPU를 빼았겼다. 여기서 80ms를 remaining time-slice라고 한다. 즉, 리눅스에서는 어떤 프로세스가 CPU를 차지하기 위해서는 우선 순위(Priority)도 높아야 하고 remaining time-slice도 0이 아니어야 한다.
Scheduling Algorithm

A는 실행가능한 task의 리스트가 있는 Ready-Queue 리스트이다. 그런데 문제는 멀티 프로세서 시스템에서 CPU가 10개, 50개, 100개가 되면 Ready-Queue 리스트가 매우 길어진다는 데 있다. 이런 비효율성 때문에 B와 같이 높은 우선순위와 낮은 우선순위로 구분해 놓았으나, B 역시 감당에 한계가 있어 C처럼 우선순위를 등급을 매겼다. 그런데 C를 보면 중간에 빈 포인터도 보이는 걸 알 수 있다. 이런 큐까지는 탐색할 필요가 없으니 탐색 속도를 향상시키기 위해 해당 우선순위 큐가 비었는지를 체크할 수 있는 Boolean 타입의 bitmap 배열을 추가했다.

위 템플릿에서 priority array라는 구조체가 있고 구조체에는 bitmap과 queue가 있는 것을 알 수 있다. bitmap[1] = 0인 것을 알 수 있다. 이는 queue[1] = null 이라는 뜻이고 1번 째로(제일 우선순위가 높은 것은 0번) 우선순위가 높은 프로세스가 없다는 것을 뜻한다. 이제 bitmap[132]를 가보자. bitmap[132]의 값은 1이므로 현재 132번째의 우선순위를 가진 작업들이 대기중인 것을 의미한다. (해당 큐의 리스트들은 PCB로 되어 있다)

사실 동작방식이 간단하다. 우선 bitmap을 스캔해서 제일 먼저 위에 있는 0이 아닌 bitmap이 우선순위가 제일 높은 queue가 있을 것이다. 위 템플릿에서는 bitmap[2]가 제일 우선순위가 높으므로 해단 ready-queue 리스트에 가서 프로세스를 실행시켜주면 된다.
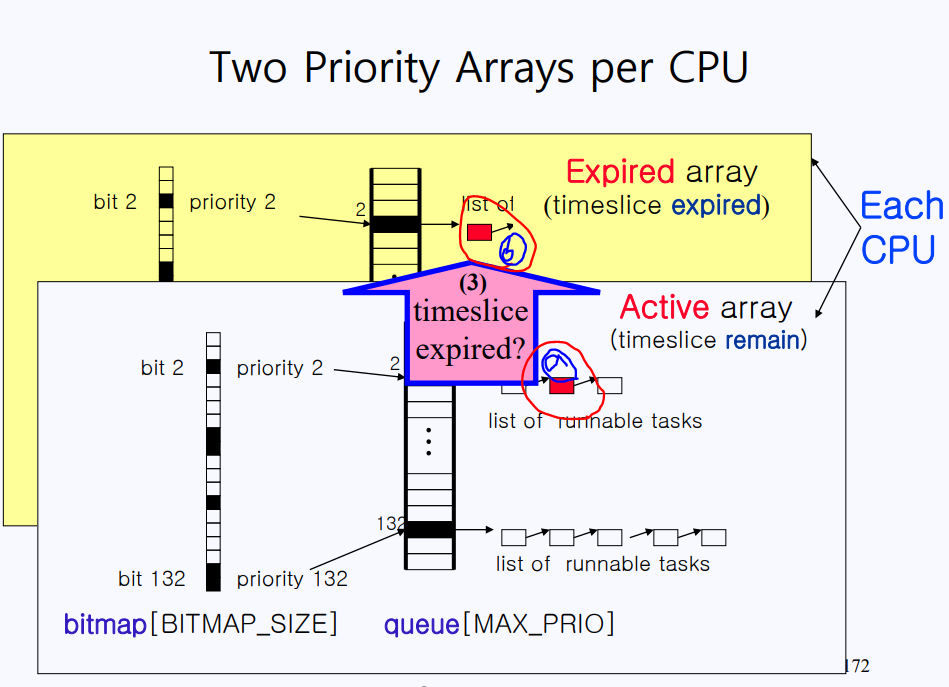
ready-queue 리스트에 가장 상단에 있는 프로세스를 실행시키는데 ⓐ 프로세스가 time-slice가 바닥이 나버렸다고 해보자, 그럼 ⓐ 프로세스는 더 이상 ready-queue 리스트에 있을 자격이 없다. 다음 time-slice를 다시 배정받기 전까지는 ready-queue 리스트에 있을 자격이 없다. 그럼 ⓐ프로세스는 어디로 가야할까? 위 템플릿의 Expired array는 time-slice가 바닥난 프로세스만 있다는 차이점만 빼고는 Active array와 완전히 동일한 구조로 되어 있다. time-slice가 바닥난 원래 queue[2] 있던 프로세스는 똑같은 우선순위에 해당하는 expired array[2]에 대기중이다. 그러다 보면 queue의 우선순위가 높은 프로세스부터 점점 expired array로 이동할 것이다. 그러다가 결국엔 queue에 있는 프로세스들이 전부 expired array로 가면, 일률적으로 다시 time-slice를 배정한다. 자, 좀 전에 언급했듯이 Expired array는 Active array와 구조가 완전히 동일하다. time-slice가 배정된 이후부터는 Expired array가 Active array가 되고, Active array사 Expired array가 된다. 이것이 리눅스의 O(1) 스케줄링 과정이다.



Kernel Preemption(커널 선점)

컴퓨터 시스템에 대해서 공부할 때, 가장 중요한 파트 중 하나가 바로 Mutual Exclusion(상호 배제)이다. 시스템이 제대로 동작하기 위해서는 이 상호 배제 이슈를 잘 관리해줘야 한다. 밑의 예에서는 x++ 연산을 예시로 들어서 설명할 건데 그 전에 x++ 연산이 어떻게 진행되는 자세히 알아보자.
x++ 연산은 쓰여있기로는 코드 한 줄이지만 내부적으로는 크게 3단계로 이루어진다.
1) x++를 하기 위해서는 x가 필요하다. x는 어디에 있는 걸까? CPU 안의 데이터를 저장할 레지스터라는 공간이 있지만, 데이터는 수 백, 수 천만 개가 있으므로 레지스터에 전부 저장하기에는 턱없이 부족하다. 그래서 x는 storage(스토리지)에 저장돼 있다. ++ 연산은 CPU에서 해야하므로, x를 레지스터로 읽어오는 것부터 한다.
2) cpu에서 ALU 연산(++)을 한다.
3) 연산 결과를 레지스터로부터 다시 스토리지에 저장한다.

서로 다른 프로세스 A와 B가 공유하고 있는 변수 x에 대해서 ++ 연산을 한다고 생각해보자. 위에서 언급했듯이 x++ 연산은 단순히 코드 한 줄이지만 실제로 연산이 이뤄지는 단계는 3단계다. 프로세스 A가 x = 11이었던 값을 스토리지로부터 읽어와서 레지스터에서 연산을 해 12로 만든 후, 다시 스토리지에 저장했다. 그 후, 프로세스 B가 다시 스토리지에 저장된 x값(12)을 레지스터로 읽어와서 연산 후, 13을 다시 스토리지에 저장했다. 이건 바람직한 결과이다. 그런데 만약에 프로세스 A가 2단계 연산(ALU가 연산)을 하는 중, 프로세스 B가 연산을 시작한다면? 즉, 프로세스 A가 아직 결과값을 스토리지에 저장하지 않은 채, 프로세스 B가 x=11이라는 값을 가져와서 연산한다면? 결과적으로 x는 프로세스 A와 B가 x=11인 상태로 연산을 했기 때문에 x는 13이 아니라 12가 될 것이다.
두 개의 프로세스가 이렇게 공유된 변수에 접근하는 것을 Critical section 혹은 Critial region이라고 한다. 그래서 Critical section은 두 개 이상의 프로세스가 동시에 접근하면 안 되고 반드시 한 번에 하나의 프로세스만이 접근해야 한다. 이것을 상호 배제 원칙(Mutual Exclusion)라고 한다. 절대로 동시에 접근하면 안 된다.
자, 이제 다른 상황을 가정해보자. 프로세스 A와 프로세스 B가 있다. 프로세스 A는 유저모드 -> 커널모드 -> 유저모드 이런 식으로 반복되면서 실행될 것이다. 프로세스 A가 유저모드일 때 CPU를 프로세스 B에게 뺐기는 건 상관이 없다. 왜냐하면 두 프로세스가 현재 공유하는 변수가 있다하더라도 유저모드에서는 자기 변수밖에 접근할 수 없으니까. 그런데 문제는 프로세스 A가 커널모드일 때 CPU를 뺐길 때 발생한다. 이게 왜 문제냐고? 프로세스 A가 커널모드에서 공유된 변수 x에 접근해서 x++를 하던 중, CPU를 프로세스 B에게 뺐겼다. 프로세스 B역시 유저모드 -> 커널모드 -> 유저모드 -> 커널모드 이런 식으로 실행되다가, 프로세스 B 역시 커널모드에서 공유된 변수 x에 접근해서 x++ 연산을 실행한다면? 아까와 같이 상호 배제 이슈가 발생한다!!
이 문제를 지난 40년 간 유닉스가 채택한 해결방법은 간단하다. 프로세스 A가 CPU로 점유한 동안 인터럽트가 발생했다면 CPU를 넘겨줘야 할 것이다. 그런데 인터럽트가 걸린 시점에 CPU가 유저모드이면 CPU를 넘겨주지만 커널모드이면 넘겨주지 않는다. 즉, 현재 CPU가 유저모드이면 CPU를 넘겨주지만 커널모드일 경우에는 커널모드가 끝나고 유저모드로 돌아가야 CPU를 넘겨준다. --> No CPU Preemption In Kernel
그런데 이러한 접근법에는 분명 문제가 있다. 아무리 CPU가 커널모드라도 급하게 처리해야 하는 요청이 있는 경우에는 어떻게 대응할 것인가라는 이슈가 남는다. 즉, 실시간(real-time) 처리를 하는 데 적합하지 않다. 안드로이드 OS를 생각해보자. 안드로이드에는 여러 앱들이 돌아간다. MP3 앱으로 노래를 듣고 있는데, 한 곡이 끝나면 바로 다음 곡이 재생되는 게 일반적이다. 그래서 한 곡이 끝나고 다른 곡을 틀으려고 CPU를 요청하는 데 CPU가 다른 프로세스 때문에 현재 커널모드라고 CPU를 안 주면 어떡하지? 그럴 때는 커널모드라도 CPU를 뺐어올 수 있어야 한다.

*Kernel Stack: 유저모드에서 함수 콜은 User Stack에 쌓인다. 반면에 시스템 콜은 커널 함수이기 때문에 Kernel Stack에 쌓는다. 시스템 콜이 쌓이는 커널 스택은 유저 메모리에 두지 않고 커널 메모리에 둔다. 스택이란 함수에서 생성된 로컬 변수가 모두 저장되므로 시스템 콜에서 선언된 모든 로컬 변수 역시 커널 스택에 저장된다.
위 템플릿에서 쉘과 메일이 각각 시스템 콜을 호출하는 걸 볼 수 있다. 쉘이 read를 호출해서 read 시스템 콜 안에 있는 변수는 커널 스택에 저장되고, 마찬가지로 main이 send라는 시스템 콜을 호출하면 send 내에 있는 로컬 변수가 커널 스택에 저장될 것이다. 그러다가 read와 send가 Global Variable에 동시에 접근하면 어떻게 될까? 즉, 커널이 read 함수나 send 함수 내의 로컬 변수를 read, write 할 때는 언제든지 CPU로 뺐겨도 상관없지만, 위의 상황과 같이 공용(전역) 변수에 접근하고 있을 때는 CPU를 빼았아 가선 절대 안 된다.
리눅스에서는 공용 변수에 접근할 때만 따로 lock을 건다. 접근이 완료되면 unlock을 한다. 즉, lock이 걸린 상태에서는 절대 CPU를 뺐기지 않는다. 또한, 공용 변수 여러 개에 접근했을 경우에는 따로 카운터를 해서 카운트가 0이면 현재 공용 변수에 접근하지 않고 있다고 간주, CPU를 넘겨준다.

preempt_count 변수는 공용 변수에 접근할 때마다 count를 증가시키고 접근이 끝나면 감소시킨다. preempt_count 값을 보고 lock을 풀지 말지 결정한다. CPU를 빼았으러 왔다가 preempt_count가 0이 아니면 CPU를 뺐지 못한다고 했다. CPU를 뺐지 못했더라도 need_resched(need_rescheduled) 플래그를 set한다. need_resched 플래그가 세팅돼 있으면, preempt_count가 0이 되는 순간 need_resched값이 세팅돼 있으면 CPU를 넘겨줘야 한다.


Timers and Time Management

우리가 평소에 사용하는 아날로그 시계는 1초마다 시침이 째깍째깍 움직이는데, 영어로 tick-tack 이라고 표현한다. 이 대 1초에 1000번 째깍거리면 1000HZ라고 하고 1 밀리세컨드(Millisecond)가 된다. C에서 #define HZ 1000이라고 선언하면 해당 시스템은 1초에 1000번 인터럽트(Interrupt)가 걸린다. 대부분의 아키텍쳐에서는 #define HZ 100으로 선언한다.
시스템을 부팅(Booting)한 이후로 몇 번 tick-tack 했는지를 알기 위해 jiffies 변수를 사용한다. jiffies는 전역 변수로서 시스템이 부팅하면 그 이후로 계속 카운트를 한다. 즉, HZ가 100이면 1초에 100번 째깍째깍하므로 시스템이 시작한 후로 1초가 지나면 jiffies 값은 100이 되어있을 것이다. jiffies를 이용하면 시스템이 부팅한 이후로 몇 초가 흘렀는지 알 수 있다. 위 템플릿에서 jiffies 값이 274050이다. 보통의 시스템이 HZ를 100으로 설정하기 때문에 274050 / 100 하면 2740.5이므로 시스템이 부팅한 이후로 2740.5 초가 흐른 것을 알 수 있다.


