PCB(Process Control Block)이란?
- 운영체제가 프로세스를 제어하기 위해 정보를 저장해 놓은 곳으로, 프로세스의 상태 정보를 저장하는 구조체이다.
- 프로세스 상태 관리와 문맥 교환(Context Switching)을 위해 필요하다.
- PCB는 프로세스 생성 시 만들어지며 RAM에서 유지된다.
즉, PCB는 OS가 프로세스에 대한 중요한 정보를 저장해 높을 수 있는 저장 공간이다. 프로세스가 실행 중이라면 CPU의 레지스터에 현재 실행 중인 프로세스에 대한 정보가 있기 때문에 PCB라는 별도의 공간에 프로세스 정보를 저장할 필요가 없다. 하지만 인터럽트가 걸려서 Context Switching이 발생하면, 현재 실행 중인 프로세스는 작업을 마치지 못한 채 CPU의 사용권한을 반납해야 하기 때문에, 프로세스의 작업을 이어서 마무리하기 위해서 현재 어디까지 작업이 진행됐지는 같은 정보를 저장하기 위해 PCB가 필요하다.
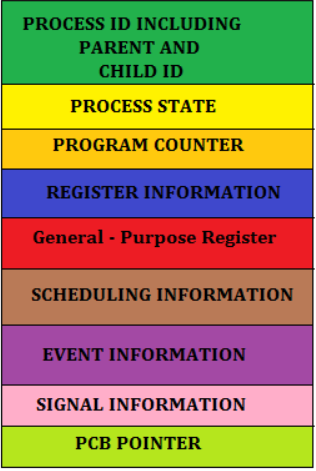
- Process ID : 프로세스를 구분하는 ID
- Process State : 각 State 들의 상태를 저장한다.
- Program Counter : 다음 Instruction 의 주소를 저장하는 카운터. CPU는 이 값을 통해 Process 의 Instruction 을 수행한다.
- Register : Accumulator, CPU Register, General Register 등을 포함한다.
- CPU Scheduling Information : 우선 순위, 최종 실행시간, CPU 점유시간 등이 포함(***)된다.
- Memory Information : 해당 프로세스 주소공간(lower bound ~ upper bound) 정보를 저장.
- Process Information(페이지 테이블, 스케줄링 큐 포인터, 소유자, 부모 등)
- Device I/O Status(프로세스에 할당된 입출력 장치 목록, 열린 팔린 목록 등)
- Pointer : 부모/자식 프로세스에 대한 포인터, 자원에 대한 포인터 등
- Open File List : 프로세스를 위해 열려있는 파일의 리스트
프로세스 생성(Process Create)
Child Proces를 생성할 때 총 2번의 오버헤드(Overhead)가 발생하는데. 이 오버헤드들은 fork()를 하는 도중 발생한다. 첫번째 오버헤드는 부모의 image를 자식에게 복사하며 생기고 두번째는 PCB를 복사하며 생긴다.

PCB의 정보들은 수십(?) 수백(?) KB로 이루어져 있다. PCB의 내용을 분류해보자면,
- task basic info: ?
- files: 프로세스가 Open한 파일들에 대한 정보
- fs: 프로세스가 접근 중인 file system에 대한 정보(e.g. c를 마운트하고, d를 마운트하고...)
- tty: 현재 프로세스가 사용 중인 터미널에 대한 정보
- mm: 프로세스가 사용 중인 메인 메모리에 대한 정보
- signals: ?
리눅스는 이렇게 분류된 elements들을 6개 struct로 분리해서 관리한다.

위 템플릿의 왼쪽 박스에 나와있는 것처럼 크게 task_struct(PCB)가 있다. 이건 리눅스가 가지고 있는 PCB인데 그 안에는 여러개의 struct들에 대한 내용이 있고 그 옆에 보라색으로 *mm, *tty등이 있는 것을 알 수 있다. 이 포인터(*)들을 따라가면 오른쪽 그림에서도 알 수 있듯, 각각이 가르키는 파일, 메모리 등에 접근할 수 있다. 이처럼 리눅스의 PCB는 task_info 하나의 구조체가 아니라 1(task_info)+5(files, fs, tty, mm, signals)=6개의 구조로 나눠져 있다. 리눅스는 그럼 PCB 왜 이렇게 6등분으로 나누어 놓았을까?

Child를 만드려면 사실 6개의 구조체를 전부 복사해주면 쉽다. 그러나 task_info에 먼저 접근한 다음 files에 접근해서 copy해주고, 다시 task_info에 접근한 다음, fs에 접근해서 write해주고... 이 과정은 너무 비효율적이며 자원 낭비가 심하다(read by -> write by -> read by -> write by ... -------> heavy-weight creation)
하지만, shell(Parent)가 쓰는 file system이랑 child가 쓸 file system이 차이가 날까? 또한, parent가 쓸 tty랑 child가 쓸 tty가 차이가 날까? --> 즉, Task basic Info는 복사를 해주되, 자식의 files, fs, tty, mm, signals는 부모의 것을 같이 쓰면 된다. 어떻게 같이 쓸 수 있을까? 간단하다. Task basic Info 안에 포인터만 부모의 files, fs, tty, mm, signals로 향하면 된다. 당연히 heavy-weight creation보다 복사를 덜 하므로 오버헤드도 줄어든다 ------> light-weight creation

위 템플릿에서 보는 바와 같이 게임 프로세스가 있다고 해보자. 가운데 검은 상자는 메인 메모리다. 여러 개의 CPU가 있고 CPU마다 PC(Program Counter)가 있는 걸 알 수 있다. Parent Process가 존재하고 Parent Process만의 PCB도 존재하는 걸 알 수 있다. 이제 똑같은 Child로 만들어주려고 하면 a.out도 copy해주고 PCB도 copy해줘야 한다. 두 작업보다 생각보다 오버헤드가 매우 크다. ---> Heavy-Weight Creation. 그럼 어떻게 해야할까?

Heavy-Weight Creation 오버헤드를 줄이기 위해서는 Parent의 모든 PCB를 복사해서 Child를 생성하는 게 아닌, CPU에 대한 정보를 가지고 있는 Task basin info만 가지고 Thread로 생성하는 것이다. 즉, Thread로 만들어준다는 말의 의미는 Child를 만들 때, Task basic info, file, fs, tty, mm, signals 전부를 복사해서 Child에게 주는 게 전통적인 방식의 Headvy-Weight Creating이라면 files, fs, tty, mm, signals를 제외한 Task basic info만 복사하고 files, fs, tty, mm, signals는 Parent와 공유한다. 이를 Light-Weight Creation이라고 한다.

- Child는 Pointer를 이용해 Parent의 PCB 데이터를 공유한다
- Child가 생성되는 동안 최소한의 복사만 할 수 있어서 오버헤드를 줄일 수 있다.
- 리눅스에서 스레드는 일반적으로 사용하는 스레드와 개념이 다르다. 즉, Child Creation을 하는데 Light하게 생성해주는 걸 스레드라고 한다.(Light-weight Process) 그리고 그걸 해주는 시스템 콜이 fork가 아닌 clone이다.

clone() 시스템 콜을 실행할 때는 파라미터로 바이너리 비트 5개를 같이 보낸다. 만약 바이너리 비트 5개가 전부 clone(11111)이면 heavy-weight copy를 하고, clone(11110) 같이 하나라도 0이 있으면 0에 위치하는 요소는 복사하지 않는다. 제인 LWT는 clone(00000)이다.

Process Copy


앞서 말한 것처럼 Parent가 Child를 복사하는 중에 발생하는 2가지 오버헤드가 있다고 했는데, 첫 번째는 Parent의 이미지*(소스코드)를 복사할 때, 두 번째는 Parent의 PCB를 복사하는 오버헤드가 있다. 그런데 PCB보다 이미지를 복사하는 오버헤드가 더 비용이 크다. 예를 들어, shell에게 ls를 요청하면 바로 ls 명령을 수행하는 것이 아니라, child shell을 만든 다음(PCB)에 ls(이미지)를 오버로드하다. 솔직히 바보같은 짓이라고 생각할 수 있다. 왜냐하면 어차피 ls 파일로 바로 overload를 할 건데, 왜 Parent의 이미지를 복사해오는 걸까? 처음부터 그냥 ls하면 되지 않을까? 대부분의 Parent -> child copy를 했을 때는 PCB를 복사해준 다음에 이미지로 덧씌우지만, 모든 사람이 Child를 다른 이미지로 덮어씌우지 않고 Parent와 Child를 똑같이 사용하고 싶은 요구도 있기 마련이다. 이런 딜레마가 존재한다. 대부분은 바로 overload 해서 새로운 부모 프로세스와 전혀 상관없는 프로세스로 사용하지만, 그 중에는 그대로 사용하고 싶은 요구도 있으므로 이를 절충한 것이 'Page Mapping Table' 만 복사하는 것이다. 결국 Child는 Parent의 이미지를 복사(즉, Parent 프로세스 자체)하는 게 아닌, Parent의 이미지를 가리키는 Page Mapping Table만 복사해오는 것이다. 즉, Child는 이미지가 있는 거 같지만 Parent의 이미지를 공유하고 명령을 수행한다. 이렇게 하면 문제는 Parent나 Child가 어떤 페이지에 대해서 Read가 아닌 Write를 할 때 발생한다. 그럴 때는 어떻게 해야 할까? 이럴 경우는 어쩔 수 없이 해당 페이지에 대해서만 Parent와 Child가 별도의 페이지를 가진다.
※ 페이지 테이블: 페이징 기법에 사용되는 자료구조로서, 프로세스의 페이지 정보를 저장하고 있는 테이블이다. 테이블 내용은 해당 페이지에 할당된 물리 메모리의 시작 주소를 담고있다.
※ 페이징 기법: 컴퓨터가 메인 메모리에서 사용하기 위해 2차 기억 저장소부터 데이터를 저장하고 검색하는 메모리 관리 기법
페이징 테이블이란?


위 템플릿의 왼쪽 그림과 같이 메모리 안에 프로세스 A, B, C가 있다고 하자. 프로세스 D를 실행시키기 위해서 프로세스 D를 메모리에 얹어야 하는데 마땅한 공간이 없다. 군데군데 빈 공간(Hole)이 보이지만 Process D가 전부 들어갈 만한 공간은 없다. 그렇다고 프로세스를 조각내서 메모리에 저장하면 프로세스가 제대로 동작하지 않을 테니, 방법이 없다. 이런 문제를 외부 단편화(External Fragmentation)가 발생했다고 표현한다.
외부 단편화를 해결하기 위해 등장한 기술이 페이징이라는 기술이다. 페이징은 프로세스를 일정 크기인 페이지로 잘라서 메모리에 적재하는 방식이다. 페이징은 위 상황처럼 전체적인 메모리 공간으로는 충분히 여유가 있는데도 불구하고 연속된 메모리 공간이 없어서 프로세스를 얹을 공간이 없을 경우를 해결하기 위해 사용된다. 이제 오른쪽 그림으로 가자. 프로세스 A랑 프로세스 B가 있다. 프로세스 A는 page 0 ~ page 5의 합으로 이루어져 있고, 프로세스 B는 page 0 ~ page 3의 합으로 이루어져 있다. 이러한 쪼개진 프로세스들을 물리적 메모리(physical memory)에 무작위로 저장해 놓고 페이지 매핑 테이블이란 곳에 해당 페이지에 대한 주소를 기록한다. 즉, 메인 메모리에는 프로세스의 메모리가 떨어져서 저장되어 있지만 페이지 매핑 테이블을 이용해 논리적으로는 서로 붙어있는 효과를 낸다.

Child가 시작할 때는 독자적인 이미지는 없고, 페이지 테이블만 가지고 있다. 그러다가 Child나 Parent에서 Page에 Write할 경우가 '해당' 페이지에 대해서만 copy를 해서 별도로 나눠갖고 그 이외의 페이지 테이블에 대해서는 계속 공유한다.
보통 Parent가 fork를 한 이후에 wait를 하지만, 그렇지 않은 경우도 많다. 이를 테면, Parent가 fork를 한 이후에 다른 작업을 하다가 wait를 하는 것이다. 그 다른 작업 중에서는 write도 포함될 것이다. 만약 Parent가 fork 이후에 여러 write를 하면 write한 부분에 대해서는 Child와 다른 페이지를 공유할 것이다(COW). 이렇게 여러 write 작업 후에 Parent가 wait을 했다고 치자. 그러면 CPU는 Child에게 넘어갈 것이다(여기서는 프로세스가 Parent와 Child밖에 없다고 가정하자. 다른 프로세스가 있다면 ready-queue에서 프로세스 우선순위가 제일 높은 프로세스가 CPU 사용 권한을 받는다). Child에게 자, 이제 CPU 사용 권한이 넘어왔다. 그런데 Child가 바로 ls 같은 명령 수행을 위해 ls 파일로 이미지 overload를 하면 어떻게 할까? 바로 overload 하는데 Parent는 왜 COW를 한 것일까? 너무 자원 낭비 아닌가?

(위 템플릿) Parent가 COW를 했지만 Child는 바로 exec(ls)를 하기 때문에 자원 낭비가 심하다.

COW 낭비를 해결하기 위해 리눅스는 fork 시스템 콜을 다시 설계(Redesign)했다. fork()가 끝나면 Parent에게 돌려보내지 않는다. 원래 fork()가 끝났어도 Parent가 wait 시스템 콜을 호출하지 않는 이상 Parent의 CPU 사용 권한은 뺐기지 않는다. 그래서 fork를 할 때, Child의 Priority를 전격적으로 높인다.
시스템 콜을 사용할 때는 항상 커널모드에서 실행되야 한다. 즉 fork() 역시 실행되기 위해서는 커널모드에서 실행되어야 한다. fork()가 끝나면 커널모드에서 다시 유저모드로 돌아가야 하는데, 이 때는 항상 ready-queue list에서 제일 우선순위가 높은 프로세스에게 CPU 사용 권한이 할당된다.
<정리>
step 1) fork()가 실행되면서 Child가 생성하고 ready-queue list에 삽입하면서 제일 우선순위를 높여놓는다.
step 2) fork 같은 시스템 콜이 끝나고 커널모드에서 유저모드로 돌아갈 때는 자동적으로 돌아가지 않고 항상, ready-queue list에서 제일 우선순위가 높은 아이한테 CPU를 할당한다.
step 3) Child가 Parent보다 우선순위가 높으므로 Child에게 CPU가 간다.
step 4) Child는 CPU를 받자마자 바로 exec을 해버리기 때문에 Parent에서 있었을지도 모르는 COW 낭비를 막을 수 있다.
해당 내용이 다음 템플릿에 잘 설명돼 있다.

커널 스레드(Kernel Thread)

스레드 vs 프로세스
앞에서 배운 언급한 것처럼 프로세스와 스레드를 구분하면 다음과 같다.
프로세스는 부모의 자원을 무식하게(heavy-weight creation) 전부 카피(Task basic info + file, fs, tty, mm, signals)
스레드는 필요한 것만 카피(light-weight creation) 나머지는 부모의 이미지를 가리키는 Parent Mapping Table만 복사한다.
위 템플릿에서 보라색 박스는 커널 영역이다. 커널은 메모리 레지던트 프로그램(부팅할 때부터 kernel a.out이 메모리에 상주)이다. 즉, 시스템이 부팅하면 커널의 main()부터 실행이 된다. 커널 프로세스가 동작하던 중 clone을 할 수 있다. 커널 프로세스가 clone을 하면 light-weight Child가 생성되는데 위 템플릿에서는 2개의 child가 생성됐다. 이 2개의 커널 스레드는 서버(데몬)로 동작하는 경우가 많다. 프린트 서버, 웹서버 같은 서버(데몬)들은 전부 커널 스레드이다.

위 템플릿에서 커널 프로세스가 있고, 두 개의 커널 스레드가 생성되었다. Child 스레드 각각이 프린트 서버(데몬), pageFault 서버를 맡고 있다. 스레드는 부모의 PCB 전부를 복사하지 않는다. 각각의 스레드는 CPU State vector(Program Counter, Stack Pointer)가 있는Task basic info만 복사하고 나머지(files, fs, tty, mm, signals)는 부모 것을 공유한다. 이게 무슨 말이냐? 각각의 스레드는 부모로부터 Task basic info를 복사해왔다. Task basic info 안에는 state vector save area가 존재하기 때문에 각 스레드마다 별도의 Program Counter와 Stack Pointer를 가질 수 있다. 즉, 각 스레드는 커널 프로세스(부모)와 별개로 개별적으로 커널 내의 다른 시스템 콜을 실행할 수 있다는 의미이다.

CPU가 running에서 I/O 작업이 생기면 해당 프로세스는 waiting이 되고 I/O가 끝나면 waiting에서 ready-list queue에 들어가서 다음 차례를 기다린다. 그러다 해당 프로세스의 차례가 오는 것을 Scheduler dispatches라고 한다. 특정 프로세스에게 CPU 사용권한을 주면 계속해서 CPU를 차지하는 게 아니라 일정 시간 타임 퀀텀이 지나면 CPU를 뺐기고 ready-list 맨 뒤로 가서 대기하게 된다. 그렇게 CPU를 뺐기다 받았다를 반복하다가 주어진 작업을 완료하면 exit() 시스템 콜이 호출되면 프로세스의 상태는 좀비상태로 변하게 된다. 좀비 상태는 뭐냐? 좀비라는 표현을 쓰는 이유는 프로세스의 흔적이 남았다는 의미로 사용된다. 좀비 상태는 a.out도 날라가고, file도 전부 close되고 메인 메모리도 전부 빼았긴 상태이다. 그렇다면 무엇이 남아있느냐? 바로 프로세스의 PCB만 남아있다. PCB를 없애지 않는 이유는 프로세스를 exit하면 프로세스가 종료되고 해당 프로세스의 Parent가 깨어나서 실행이 될 것이다. 그렇다면 Parent 입장에서는 Child가 CPU를 얼마나 썼는지, Disk를 얼마나 썼는지, 정상 종료되었는지 같은 정보를 알고 싶다. 바로 그 정보가 Child 프로세스의 PCB에 기입돼 있다. 그래서 마지막으로 Child 프로세스의 PCB를 말소하는 것 역시 Parent 프로세스가 하는 일이다.
'CS > Linux' 카테고리의 다른 글
| Linux Kernel: System Call (0) | 2021.01.01 |
|---|---|
| Linux Kernel - Introduction (0) | 2020.12.30 |

