
모든 I/O Library 함수는 원천적으로는 I/O Instruction을 가질 수 없다. 그래서 해당 printf나 scanf 같은 모든 Library 함수는 System Call을 부른다. 이 과정을 wrapper routine이라고 한다. 이 wrapper routine(wrapper routine 안에는 왜 커널로 가게 되는지 알려주는 정보들을 담고 있는Prepare parameter와 CPU의 모드 비트를 커널로 바꾸는 chmodk가 있음) 안에 들어가면 chmodk(Change MODE_BIT Kernel)이 있고 chmodk 하기 전에는 kernel로 가는 목적을 기록하는 prepare parameter가 있다. 즉, 이 과정은 컴파일하는 과정에 일어나며, 컴파일러는 I/O Library 함수를 사용하면 chmodk라는 문장으로 compile해서 기계어 코드로 바꾼다. 실제 I/O Instruction은 Run time에 Kernel 안에 들어가서 실행된다.

Wrapper Routine이란 이제 실제로 트랩에 타고 갈 내용들을 준비하고 트랩을 일으키는 공간이다. Wrapper Routine에서 (인텔의 경우) $0x80등 의미 없는 문자들을 이용해 Instruction을 줘 트랩을 발생시킨다. 트랩을 일으키기 전에 무엇 때문에 트랩을 발생시키는 것인지를 기록하는 Prepare parameter들을 준비해야 한다. 그 중에 가장 중요한 것은 system call number이다. 이 system call number는 커널이 가지고 있는 system call function의 시작 주소를 담고있는 Array(배열)의 Index 번호로 사용이 된다. 정리하면, printf 라이브러리 함수가 write로 바뀌고 write(2)에 대응하는 system_call을 요청한다. write system call을 요청하기 위해 system call number를 사용하게 되는데 system call number는 sys_call_table에 있는 sys_write(system call의 sys_로 시작한다)의 index이다. write system call이 system_call_table에서 몇 번 인덱스에 속해있는지는 컴파일러 제조사(IBM, 마이크로썬즈 .. etc)가 결정하는 것이기 때문에 컴파일러와 커널 간의 상호 약속이 돼 있어야 한다. 즉, 컴파일 제조사는 커널의 sys_call_table에 맞게 system call number를 세팅해 놓아야 한다. 만약 IBM의 컴파일러와 IBM에서 만든 리눅스 OS를 사용중이라면 system call number는 vendor에 의존적이라서 회사에서 system call number를 그렇게 부연했다면 사용자가 임의로 바꿀 수는 없다.

1) user program에서 시스템 콜을 호출
2) (intel cpu의 경우) $0x80 instruction 실행되면서 트랩을 발생시킨다.
3) 하드웨어가 CPU Mode bit를 유저모드에서 커널모드로 바꾼다
4) 하드웨어 sys_call()로 이동(커널 안에 있는 trap handler)
5) 돌아가야 할 프로세스의 컨텍스트(예를 들어 주소)를 저장
6) 레지스터 내에서 시스템 콜 번호가 유효한지 체크하고 유효하면 sys_call_table에서 starting address를 가져온다
7) 해당 system call를 호출
8) system call 작업이 종료되면 다시 커널모드에서 유저모드로 바꾼 뒤 해당 프로세스로 복귀

만약 내가 기존의 System Call의 단점을 보완해서 더 높은 성능을 내는 System Call을 만들었다고 하자. 새로운 시스템 콜을 만들었으니 당연히 새로운 시스템 콜 번호를 부여해야 할 것이다. 하지만, 해당 System Call은 (만약 내가 IBM에서 만든 Linux 환경에서 IBM에서 만든 컴파일러를 사용했다면) IBM에서 만든 컴파일러와 IBM에서 만든 OS 환경에서만 동작하기 때문에 대단히 플랫폼 의존적이라고 할 수 있다. 즉, 다른 시스템 환경에서는 내가 만든 시스템 콜을 호출해도 시스템 콜 번호를 추가하지 않았으니 해당 시스템 콜을 호출할 수 없을 것이다. 따라서 이 방법은 권장되지 않는다.



Linux에서 "man command"를 하면 해당 명령어의 매뉴얼을 볼 수 있다. 위 그림처럼 man cat을 하면 좌측 상단에CAT(1)을 볼 수 있는데 1은 그냥 user command, 2는 system call, 3은 library임을 알 수 있다.

write 같은 경우는 커널이 write만 해주면 그만이지만 read 같은 작업은 커널이 해당 데이터를 읽은 다음에 유저에게 읽은 데이터를 넘겨줄 필요가 있다. 즉, user가 데이터를 주거나 받을 필요가 있을 때는 데이터 IO가 가능한 커널과 통신할 필요가 있다. 그래서 커널은 위 그림처럼 유저의 데이터 공간에 접근할 수 있는 여러가지 함수를 장착하고 있다. kernel a.out과 user a.out은 독립된 프로그램이다. 그렇다면 독립된 프로그램의 한계를 넘어서 서로 다른 프로그램끼리 데이터를 교환할 때는 어떻게 해야할까? 리눅스는 Multi_User_System이기 때문에 시스템의 보안을 위해서 오직 커널만이 모든 메모리에 접근이 가능하다. 즉, 커널이 유저에게 데이터를 보내줄 수는 있어도 유저가 커널로부터 데이터를 읽어 올 수는 없고 커널이 유저한테서 데이터를 읽어올 수는 있어도 유저가 커널한테 데이터를 보낼 수는 없다. 앞에서 계속 강조해 왔지만 모든 I/O는 커널을 통해서만이 이루어 진다는 뜻이다.
Kernel Data Structurt 이해하기

OS는 하드웨어 자원(CPU, mem, disk, tty)을 관리하고 Application들이 정상적으로 동작하도록 지원해주는 역할을 한다. Kernel 역시 이와 동일한 역할 수행을 위해 자신만의 Data Structure를 가지는데 개략적인 구조는 위 그림과 같다.
먼저 하드웨어 관리를 위한 Data Structure안에는 각 하드웨어에 대한 정보가 담겨져 있다. 예를 들어, Memory 하드웨어에 관한 Data Structure에는 이 Memory의 크기가 어느정도이며 어디서부터 어디까지 메모리가 사용되고 있는지에 대한 정보를 관리하기 위한 내용들이 담겨있을 것이고, disk에는 현재 가용할 수 있는 disk의 크기와 사용 중인 disk의 크기 등의 정보가 있을 것이다.
하드웨어처럼 프로세스들을 관리하기 위한 Data Structure 또한 있어야 할 것이다. 우리는 이러한 Data Structure을 PCB(Process Control Block)이라고 부른다. PCB는 이름에서도 유추할 수 있듯이 운영체자가 프로세스를 지원하고 프로세스에 대한 중요한 정보들이 담겨있는 데이터 구조체이다. 즉, 특정한 프로세스를 관리할 필요가 있는 정보를 포함하는, 운영체제 커널의 자료구조이다. PCB는 운영 체제가 프로세스를 표현한 것이라 할 수 있다. PCB의 역할을 제대로 이해하려면 Context Switching에 익숙해질 필요가 있다.
예를 들어, CPU가 처리해야할 급한 프로세스 요청이 들어오면 현재 실행중인 프로세스를 잠시 중지할 필요가 있다. CPU는 한 번에 하나의 프로세스밖에 처리를 못하므로 현재 프로세스 정보를 어딘가 저장해놓아야 할 것이다. 물론, 프로세스가 실행중인 와중에는 프로세스 관련 정보들은 레지스터에 있겠지만, 실행중인 프로세스가 interrupt 되고 waiting 상태로 바뀌면, 다른 프로세스의 정보가 register에 채워질 것이므로 현재 레지스터에 저장된 프로세스 정보를 PCB에 저장해놓는 것이다. 저장해놓지 않는다면 다른 프로세스 요청을 처리하고 다시 원래 처리해야 할 프로세스를 실행시킬 때 어디서부터 실행시켜야 하는지에 대한 정보가 없으므로 처음부터 다시 실행해야 한다. 그 정보를 저장해놓는 공간이 앞서 설명한 PCB이다.
PCB의 역할에는 다음과 같은 것들이 있다.
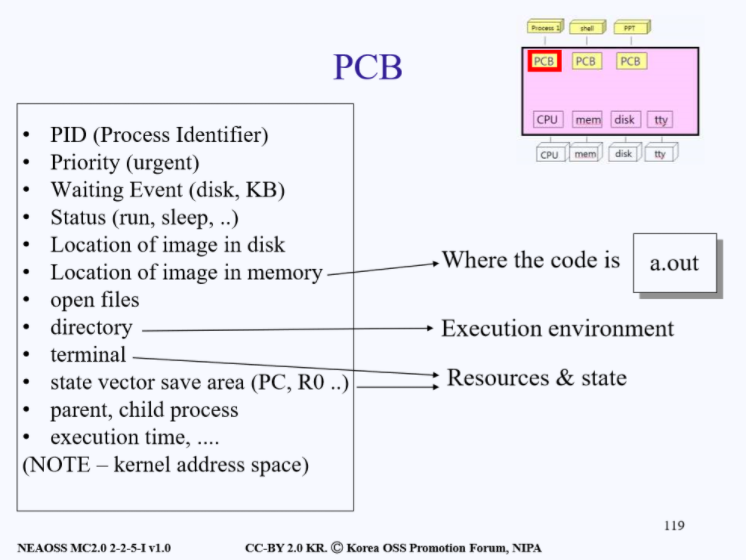
- 운영체제가 프로세스 스케줄링을 위해 프로세스에 관한 모든 정보를 가지고 있는 데이터베이스를 PCB라고 한다.
- 운영체제에서 프로세스는 PCB로 나타내어지며, PCB는 프로세스에 대한 중요한 정보를 가지고 있는 자료이다. 각 프로세스가 생성될 때마다 고유의 PCB가 생성되고, 프로세스가 완료되면 PCB는 제거된다.
- 프로세스는 CPU를 점유하여 작업을 처리하다가도 상태가 전이되면, 진행하던 작업 내용들을 모두 정리하고 CPU를 반환해야 하는데, 이때 진행하던 작업들을 모두 저장하지 않으면 다음에 자신의 순서가 왔을 때 어떠한 작업을 해야하는지 알 수 없는 사태가 발생한다. 따라서 프로세스는 CPU가 처리하던 작업의 내용들을 PCB 내에 저장하고, 다음에 다시 CPU를 점유하여 작업을 수행해야 할 위치 역시 PCB 내의 PC(Program Counter: 이 프로세스가 다음에 실행할 명령어의 주소를 가리킨다)에 저장한다. 이후 다시 CPU 파워를 점유하였을 때, PCB로부터 해당 정보들을 CPU에 넘겨와서 계속해서 하던 작업을 진행할 수 있게 된다.
- PID(Process Identifier): PID(프로세스 아이디)
- Priority(urgent): 우선 순위(하나의 프로세스만 CPU 점유를 신청한 것이 아니기 때문에 우선순위에 따라 CPU를 점유한다)
- Wating Event(disk, KB): 대기 현상
- Status(run, sleep..): 프로세스의 상태(run, sleep..)
- Location of image in disk: 이미지의 디스크 위치
- Location of image in memory: 이미지의 메모리상의 위치(코드의 위치)
- open files: 오픈 파일(유닉스에서 파일은 바이트의 연속이고 각종 디바이스 또한 전부 파일로 취급한다. 참고로 제일 먼저 오픈하는 파일은 키보드와 스크린 파일이다.)
- directory(Execution environment): 현재 프로세스 진행중인 환경
- Terminal: 터미널
- state vector save area: 상태 백터 저장 공간
- parent, child process: 부모, 자식 프로세스
- execution time: 실행 시간
Process Queue
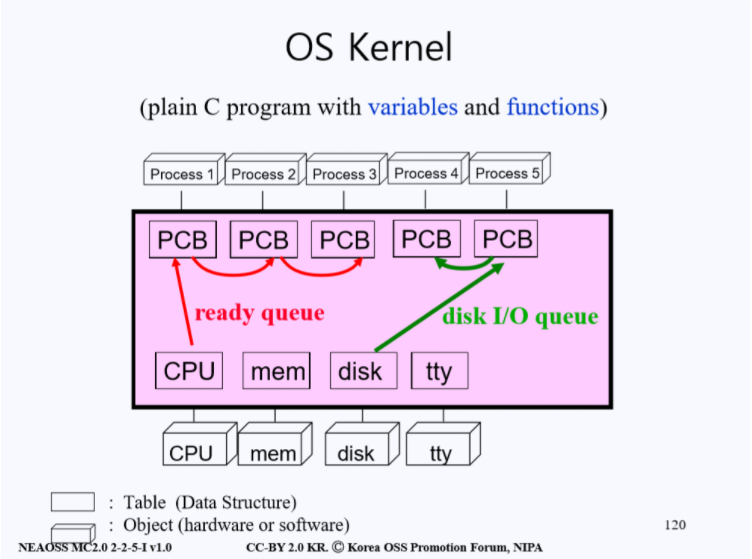
하드웨어 자원은 한정적이므로 다수가 프로세수거 이용을 희망하면 선착순으로 대기해야 한다. 즉, 프로세스는 사용하고 싶은 하드웨어(CPU, disk.. etc)가 이미 다른 프로세스에 의해 사용되고 있으면 대기표를 뽑고 기다려야 하는 일이 일어난다. 이 경우 해당 프로세스의 PCB는 본인이 사용하려 했던 하드웨어에 링크를 걸어놓고 Queue(대기열)에 들어가게 된다. 만약 본인 앞에 다른 프로세스가 똑같은 하드웨어를 사용하려고 이미 대기 신청을 한 상황이라면 먼저 기다리고 있던 프로세스의 뒷 순서로 대기 Queue에 들어간다. 이런 대기 Queue 중 CPU에 링크를 걸어놓고 기다리는 것을 ready queue라고 하고 disk에 링크를 걸어놓고 기다리는 것을 Disk I/O queue(Disk wait queue)라고 한다.
fork와 exec System Call을 이용한 Child Process 생성
Linux에서 Kernel은 메모리에 상시 거주하고 있는 프로세스이다. Kernel이 메모리에 제일 먼저 올라가고
Kernel은 기본적으로 하나의 Shell을 킬 것이다. Shell에서 사용자가 프로그램을 시작하라는 명령(가령, 파워포인트, 엑셀 ...)을 입력하면 Shell은 파워포인트를 실행하기 위해 자식 프로세스를 생성한다. 자식 프로세스 생성과정은 다음과 같다.

1) 부모 프로세스의 PCB을 복사해서 자식 프로세스의 PCB 공간을 확보해준다. 부모 프로세스의 PCB 정보를 그대로 복사하기 때문에 부모 프로세스의 환경(터미널, 키보드 등)을 자식 프로세스도 그대로 물려받는다.
2) 부모의 이미지를 똑같이 복사해서(여기서 말하는 이미지가 정확히 뭘 말하는지는 잘 모르겠다) 빈 메모리 공간에 지정해준다. --- fork
3) 디스크로부터 child의 새로운 이미지를 넣는다.
4) 현재 Parent Process가 CPU를 점유 중이므로 새로 생성된 Child PCB를 CPU의 ready-queue list에 넣어서 대기시킨다. --- exec
System Call - fork()
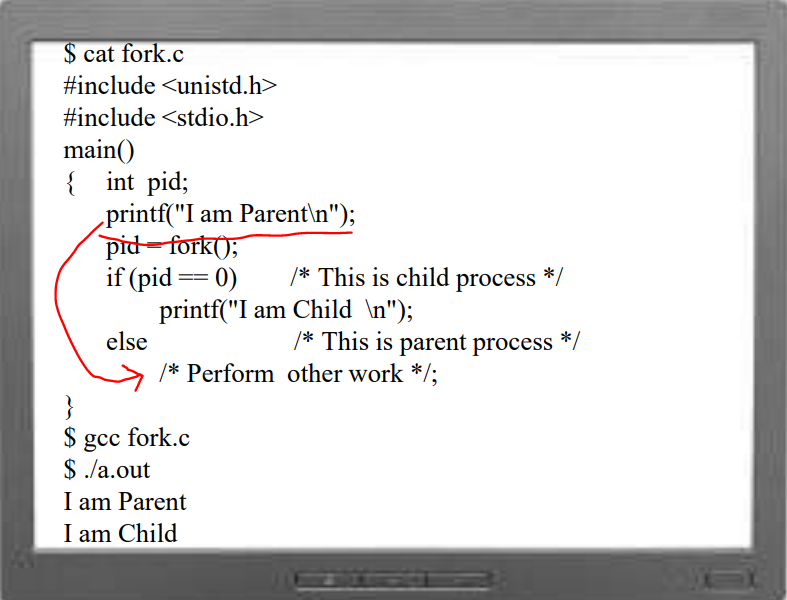
fork는 parrent 프로세스 정말 똑같이 복사한다. 여기서 부모 프로세스를 그대로 복사했다는 것은 어디서 실행해야 할지를 알려주는 PC(Program Counter)와 SP(Stack Pointer) 또한 복사되었다는 걸 의미한다. 즉, 아래 코드에서 pid = fork() 구문에서 자식 프로세스가 시작된다. 부모 프로세스는 그 다음 명령을 이어갈 것이다. 그렇다면 생성된 자식 프로세스의 시작점은 생성된 그 시점의 부모 프로세스의 이미지를 그대로 복사하기 때문에 pid=fork() 명령 다음이 된다. 부모 프로세스와 자식 프로세스가 구분되는 점은 fork() 한 다음에 return value가 상이하다는 것이다. 부모 프로세스의 return 값은 0인 반면, 자식 프로세스의 return 값은 0이 수를 리턴받는다. 즉, 위 코드에서는 fork()의 return value로 부모 프로세스와 자식 프로세스 실행 분기점이 나뉘는 것이다.
System Call - exec()

fork를 통해 자식 프로세스는 부모 프로세스와 아직까지는 똑같은 프로세스이다. 이렇게 생성된 자식 프로세스를 부모 프로세스와 다르게 해주는 게 exec이다. 위 코드에서 'execlp("/bin/data", "/bin/date", (char *) 0);' 은 bin 디렉토리에 있는 date 프로그램을 현재 프로세스에서 실행시키라는 의미이다. 즉, 생성된 자식 프로세스는 exec로 인해서 완전히 새로운 프로그램으로 덮어 씌워진다(Overwrite). Child Process가 Overwrite된 후, date 프로그램의 main으로 가서 명령을 실행한다. 새로운 프로세스가 생긴 것이 아니라 덧씌워졌기 때문에 PID는 바뀌지 않지만 프로세스를 구성하는 코드(기계어)와 데이터, 힙, 그리고 스택 영역의 값들이 exec으로 인해 새로운 프로그램의 것을 바뀌게 된다.
※ /bin 폴더는 binary의 약자로 binary 파일만 모아둔 디렉토리이다. 이 디렉토리 내에는 수많은 바이너리 파일이 있으며, 각각의 바이너리 파일은 원래 컴파일하고 나면 a.out의 형식으로 되어 있지만 제작사들이 그 이름을 프로그램 성격에 맞게 바꿔놓았다(docs, ppt, xls .. etc)
System Call - wait()

Parrent Process가 System Call wait()를 호출한다면 해당 프로세스의 CPU 사용권한은 박탈당한다(then kernel blocks P(preempt CPU).
임의의 프로세스 P_A가 wait() 시스템 콜을 호출하면, 커널모드(K)의 트랩 핸들러(Trap Handler)에 진입하여 wait( ) 시스템 콜 실행을 하게 되는데 이 때, 커널은 시스템 콜을 호출한 프로세스로부터 CPU를 뺐는다(preempt). 커널은 보통 자신의 작업을 다 하고 나면 호출한 프로세스의 유저 모드로 돌아가야 하는데, 유저모드로 돌아가지 않는다. 커널이 아닌 프로세스는 자신의 주소(address)에 한정되어 메모리에 공간에서만 read, jump 등을 수 할 수 있지만, 커널은 어디로든 가고 jmp(점프)할 수 있기 때문에 ready queue list에 가서 준비된 프로세스 중 우선순위가 가장 높은 프로그램의 PCB를 찾아서 PC(Program Counter)를 알아낸 후에 PC(프로그램 카운터)가 가리키는 쪽으로 가는 것(jmp)이다. 이 과정을preempt라고 한다.

wait( ) 시스템 콜을 호출하면, 부모 프로세스는 잠들게 된다. 자식 프로세스가 끝날 때까지 wait한다. CPU 사용권한이 자식 프로세스에게 넘어가고 자식 프로세스는 자신이 할 일을 수행한다. 자식이 하는 일 중에 execlp("/bin/date"...)" 라는 명령어가 마지막으로 있으니 해당 명령어를 마지막으로 수행하고 자식 프로세스는 중료한다. 자식 프로세스가 종료했을 때 CPU는 자식 프로세스로부터 부모 프로세스를 찾는다. 그 후 CPU는 부모 프로세스를 다시 자신의 대기명단(ready queue)에 등록시킨다. 이후 부모가 CPU 사용권한을 받았을 때가 바로 wait( ) 시스템 콜이 끝나는 지점이다. 부모는 이후 자신의 남은 일이 있었다면 해당 작업을 진행하게 된다.
비유를 들자면, 메일 프로그램을 들 수 있다. 메일 프로그램을 이용하는 목적은 상대에게 메일을 보내는 것이므로 우리는 '메일 쓰기'를 클릭할 것이고, 곧 텍스트를 입력할 수 있는 텍스트 에디터가 나타난다. 여기서 메일은 부모프로세스고 텍스트 에디터는 자식 프로세스라고 할 수 있는데, 우리가 메일 쓰기를 마치면 자식 프로세스(텍스트 에디터)가 종료하면서 부모 프로세스(메일 프로그램)가 다시 등장하게 된다.
System Call - exit()

C로 작성된 프로그램에서 main 함수 끝날 때는 exit 시스템 콜이 호출된다. 개발자가 exit을 직접 호출하지 않았더라도 컴파일러가 알아서 main 함수 마지막에 시스템 콜을 삽입하게 된다. 위 코드에서 exexlp(~)를 실행하면 자식 프로세스가 /bin 폴더의 date라는 프로그램의 프로세스로 덮어 씌어진다고 했다. 그리고 date 프로세스의 main 함수로 가서 프로세스가 실행된다. 위 그림에서도 볼 수 있듯이 exit 시스템 콜은 명시적으로 써주지 않아도 컴파일러가 자동으로 삽입을 해준다.

위 그림에는 exit(2)의 작동 원리가 좀 더 상세하게 적혀 있다. 이후 들어오는 신호들을 전부 무시해버리고, 파일들이 열려 있다면 파일들을 닫는다. 또한 메모리 영역에서 해당 프로세스가 차지하고 있는 부분(image)을 해제(deallocate) 해버리고, 부모 프로세스에게 통보한다. 그리고 exit(2)을 호출한 프로세스의 상태를 좀비(ZOMBIE)상태로 설정한다.
커널에서 일어나는 동작으로는 먼저 exit(2)을 호출한 프로세스의 CPU를 빼았고,ready queue에 있던 다른 프로세스에게 CPU를 넘겨준다. 이 과정을 스케쥴링(scheduling)한다고 표현하는데, 실제로 exit(2)을 호출하게 되면 커널 안의 schedule( ) 함수가 호출된다.
※ 좀비 상태(Zombie): 프로세스가 종료되었음에도 불구하고 메모리 상에서는 프로세스에 대한 정보가 사라지지 않은 상태. 자식 프로세스가 성공적으로 마치면 종료가 될 것이고 종료될 때는 반드시 exit을 한다. exit을 하면 자식 프로세스는 좀비 상태가 된다. 좀비 상태라는 건 a.out도 날라가고 file도 전부 closed 되고 메인 메모리에도 프로세스가 남아있지 않고 오직 PCB만 남은 상태를 의미한다. 종료할 거면 다 날려버리지 왜 PCB만 남겨두는 것일까? 만약 부모 프로세스가 자식 프로세스를 wait 하고 있으면, 자식 프로세스가 exit하면 부모 프로세스가 CPU 사용 권한을 받고 깨어나서 실행될 것이다. 이 때 부모 프로세스는 자신이 wait 할 동안 child process가 뭘 했는지, 디스크와 CPU는 얼마나 썼는지, 정상적으로 종료되었는지와 같은 정보를 child의 PCB에서 확인한다. 위와 같은 중요 정보들이 부모 프로세스에서 확인해야 하기에 자식 프로세스는 종료되었어도 자식 프로세스의 PCB은 커널에 남겨놔야 한다. 부모 프로세스가 PCB를 없앨 때까지는 자식은 zombie 상태이다. 따라서 부모 프로세스는 자식 프로세스들이 사용한 자원들을 전부 알아야만 한다.


1) 쉘에서 ls라는 명령어를 입력하면 해당 프로세스에서 작업할 수 없으니 커널은 해당 프로세스를 복사(shell의 PCB와 a.out)해서 자식 프로세스를 생성한다.
2) 복사된 자식은 아직 프로세스가 아닌 Data Structure 상태이며 이미지이다. 부모 프로세스를 단순히 복사만 했을 뿐 CPU 사용 권한은 아직 부모 프로세스에게 있다. 그래서 ready-queue list에서 대기한다.
3) 부모 프로세스가 wait 시스템 콜을 하면 Context Switching이 일어나서 부모 프로세스는 sleep 상태에 빠져들고 ready-queue list에 들어간다. 자식 프로세스는 그제서야 CPU 사용 권한을 넘겨받고 복사된 똑같은 쉘 코드를 실행한다.
4) 자식 프로세스에서 exec 시스템 콜을 만나면 disk로부터 ls 프로그램을 load하고 내가 가진 쉘에 overwrite되고 ls가 실행된다.
5) 자식 프로세스가 종료되면 exit 시스템 콜이 호출되고, exit이 호출되면 CPU의 사용자가 자식 -> 부모로 바뀐다. 이 때 커널이 wait 시스템 콜이 끝난 걸로 인식한다.
6, 7) 커널은 shell을 ready-queue에서 빼온 다음, CPU의 사용 권한을 다시 shell(부모 프로세스)에게 넘겨준다


Kernel의 경우 하드웨어를 위한 자료구조, 즉 테이블이 하나 존재한다. 그 자료구조를 위 템플릿에서는 struct CPU라고 표현하고 있다. 위 템플릿의 상황을 보자면, 먼저 CPU가 P1을 실행시키고 있다(파란 글씨로 P1 was running on CPU). 그리고 P1이 wait(2) 시스템 콜을 호출한다. 시스템 콜을 호출함으로써 커널은 CPU state vector(PC, SP 등)를 P1의 PCB에 저장해야 한다.
이렇게 상태 값을 기억하는 이유는 wait(2) 시스템 콜이 끝났을 때 wait(2)을 호출한 프로세스가 다시 정상적으로 작업을 원활하게 진행하기 위해서다. 보다시피 P1과 P2의 PCB는 커널 코드 안에 있다. 위 템플릿의 Kernel 파트를 보면, 커널에는 2종류의 자료구조가 존재하고 있다. P1과 P2에 해당하는 PCB들을 각각 하나씩 가지고 있는데, 커널 안에는 기본적으로 각 하드웨어 자원들마다(for each hardware resource) 자료구조가 존재하고 또한 각 유저 프로세스 마다(for each user processs) 자료구조가 존재하게 된다.
P1은 자신의 state vector에 해당하는 값들을 P1에 대응되는 PCB에 써주고(저장하고), CPU는 이제 그 다음 실행해야 할 프로세스에게 자신을 넘겨줘야 한다. CPU는 ready queue를 따라가서 CPU를 쓰겠다고 줄을 서 있는 프로세스들의 PCB를 살펴보고 우선순위가 제일 높은 프로세스를 선택한다. 그 프로세스가 동작하기 위해서는 그 프로세스에 해당하는 PCB로부터 레지스터 값들을 가져와서 자신이 가지고 있는 PC, SP 등에 저장해야 한다.CPU안에 있는 PC(Program Counter)가 P2의 PC로 바뀌었기 때문에 P2의 PC가 가리키고 있는 곳부터 실행(run) 된다. 이런 일을 해주는 함수 이름이 schedule 함수이다.

- schedule() 함수는 내부(internal) 함수이며 kernel a.out에게 알려지지 않은 함수이다. 즉, 커널 밖에서는 아예 호출할 수 없다. 유저가 커널과 통신하기 위해서 커널 밖에서 사용하는 게 system call이고 system call만이 커널에 접근할 수 있는 유일한 방법인다, schedule은 아예 유저가 접근조차 할 수 없는 것이다.
- schedule 함수는 exit, wait, read같은 시스템 콜이 호출한다. read가 호출하는 경우는 disk로부터 데이터를 읽는 동안 CPU를 점유하고 있는 건 자원 낭비이므로 이를 막기 위해서 schedule을 호출한다.
- schdule은 다음에 실행할 프로세스를 고른 다음, context_switch() 라는 함수를 호출한다.
- context_switch는 현재 cpu의 state vector를 퇴장하는 PCB의 state vector에 write하고, CPU를 점유하고자 하는 프로세스의 PCB의 state vector를 load한다.
- load한 PCB의 Program Counter가 가리키는 명령 위치로 이동한다.
즉, schedule은 CPU 임자가 바뀔 때마다 호출된다.
--- 컨텍스트 스위치 끝 ---
정리


※ 커널(분홍색 박스)에는 fork, wait, exec, exit같은 시스템 콜(context_switch()와 같이 내부(internal) 함수와 관련이 있다)과 하드웨어 자원마다 자료구조(struct cpu) 등이 있다.
1) fork를 하면 커널로 달려가서 parent 프로세스와 똑같은 image를 생성(아직 프로세스가 아니다).
2) 점선인 이유는 앞서 말한 대로 이미지만 만들어졌을 뿐, 아직 프로세스가 아니기 때문이다
3, 4, 5) wait() 시스템 콜이 호출되면 wait()에서 context_switch() 라는 내부 함수를 호출한다. context_switch()가 호출되면 지금 CPU의 state vector 영역에 있는 모든 값들을 해당 프로세스의 PCB에 write한다. 이렇게 저장하는 이유는 wait가 끝나고 실행될 때 PCB에 저장되어 있는 값을 보고 남은 작업을 하기 위해서다. PCB에 저장이 끝나면 ready-list에 있는 자식 프로세스의 PCB에 있는 값들을 CPU의 state vector 영역에 저장한다. 이제 해당 CPU의 state vector 영역에는 자식 프로세스의 대한 정보가 담겨 있으므로 PC를 보고 자식 프로세스가 작업을 시작해야 하는 시점으로 찾아가 명령을 수행한다.
6, 7) PID가 child 프로세스에 해당되므로 exec 명령을 수행한다
8, 9, 10, 11, 12, 13) disk에 가서 ls에 해당되는 파일을 찾는다. ls를 찾아서 자식 프로세스르 해당 ls 코드로 덮어쓴다(Overwrite). 덮어씌워진 자식 프로세스는 ls 파일의 main 함수를 실행한다. ls의 main 함수가 끝나면 exit 시스템 콜을 호출한다(설령 exit 시스템 콜을 명시적으로 호출하지 않았다 하더라도 compiler가 컴파일 시에 추가한다). exit 시스템 콜은 context_switch를 호출한다. context_switch가 호출되면 child process로부터 CPU 사용 권한을 뺐고, ready-list로부터 가장 우선순위가 높을 아이를 꺼내와서, 해당 프로세스의 PCB에서 state vector를 로드해서 CPU에 다시 Write한다.
14) CPU의 state vector에는 현재 Parent의 state vector가 있으므로 Parent의 PC가 가리키는 곳으로 가서 다음 명령을 수행한다 --> parent의 wait가 상태에서 running 상태로 바뀌고 프로세스 종료 --> shell은 다음 명령를 기다린다.
개념 정리

프로세스란 disk에 저장되어 있던 프로그램이 메모리에 올라간 상태를 말한다. a.out의 형식을 가지고 main 함수부터 시작되는 구조를 가진다. 스케줄링의 단위과 protection의 단위이며, 유저 모드와 커널 모드를 왔다갔다 하면서 실행된다.

user space의 context란?
- text: Instruction(명령)
- data: int A[] = {1, 2}은 a.out에 실제 데이터로서 메모리를 할당받는다
- bss: 만약 int B[1000000000]이 전역변수로 선언되어 있다고 가정해보자. A 배열처럼 초기값을 설정해주면 사전에 자원이 지급되므로 100만 개의 데이터를 실제 disk에 가지고 있어야 한다. 그러나, int B[100]처럼 초기값을 설정하지 않고 선언만 한다면 a.out이 저장된 디스크에는 데이터가 존재하지 않고 해당 배열이 실행 중, 즉 런타임에 메모리가 할당된다. 이 차이가 data와 bss의 차이이다. 즉, 컴파일 타임에 공간이 주어지는 건지, 로딩 타임에 주어지는 건지만 숙지하자.
- heap: 동적 메모리 할당에 쓰이는 데이터 영역
- stack: 함수 호출 등에 사용되는 자료구조(Data Structure)
1, 2, 3을 합쳐서 Context라고 부른다.
Server = Daemon

서버의 다른 이름은 데몬이라고 한다. 서버란 근본적으로 a.out이며 실행 알고리즘은 다음과 같다
1) 부팅 타임에 메모리에 올라온다.
2) 대부분의 시간은 Sleep한다. 언제까지? request가 올 때까지
3) request가 적절하면 요청을 처리해주고 처리가 끝나면 다시 Sleep한다.
즉, 서버란 하드웨어의 개념이 아니라 소프트웨어의 개념이다.

리눅스에서 ps(process state)를 입력하면 내가 사용하고 있는 프로세스를 출력하고 ps -e(extended)를 입력하면 시스템이 가지고 있는 프로세스까지 전부 출력한다.(웹서버, 프린트서버, 파일서버 ...)

보통의 데몬(서버)에는 d자가 붙는다. 웹서버는 httpd이고 ftp 서버는 ftpd라고 표현한다.
참조
'CS > Linux' 카테고리의 다른 글
| Linux - Process Management (0) | 2021.01.30 |
|---|---|
| Linux Kernel - Introduction (0) | 2020.12.30 |

